5 Genetics and Evolution
5.6 Molecular basis of inheritance
Molecular basis of Inheritance
Dr V Malathi
DNA
The genetic (hereditary) material for all living things is composed of DNA (deoxyribonucleic acid). It is the blue print of an organism. The DNA stores the coded information that control the biological function of cells.
The genetic material transmits this hereditary information in a stable form for the cell and organism through a molecular process called replication of DNA.
The replication process ensures high accuracy in copying the genetic information so that all progeny cells receive the same information.
Chemical Structure of DNA Subunits
DNA is a polymer made of nucleotide subunits.
A nucleotide consists of 3 chemical groups; a sugar, a phosphate and a nitrogenous base . In the case of DNA, the sugar is deoxyribose and in Ribonucleic acid (RNA), the sugar is ribose
DNA contains four types of nitrogenous bases namely Adenine (A) and guanine (G) , which are double-ringed purines, and cytosine (C) and thymine (T) , which are smaller, single-ringed pyrimidines. The nucleotide is named according to the nitrogenous base it contains.

“DNA Nucleotide” by Charles Molnar and Jane Gair is licensed under CC BY 4.0
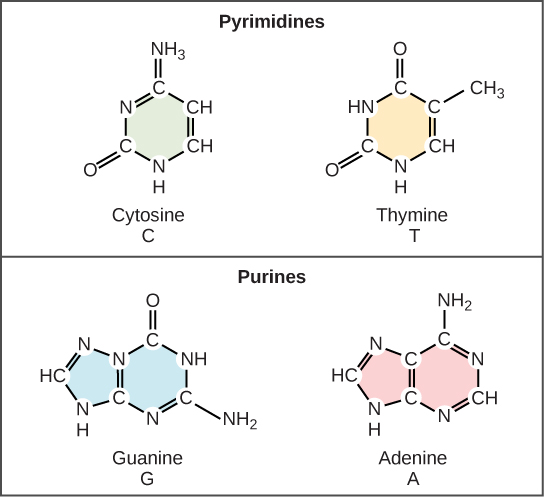
“Purines and Pyrimidines” by Charles Molnar and Jane Gair is licensed under CC BY 4.0
DNA molecule is actually composed of two single strands held together along their length with hydrogen bonds between the bases.
Each of the DNA strand is a long polymer of nucleotides is formed by the nucleotide polymerisation where a phosphate group of one nucleotide bonds covalently with the sugar molecule of the next nucleotide, and so on, .
The sugar–phosphate groups line up in a “backbone” for each single strand of DNA, and the nucleotide bases stick out from this backbone.
The carbon atoms of the five-carbon ,deoxy ribose sugar are numbered clockwise from the oxygen as 1′, 2′, 3′, 4′, and 5′ (1′ is read as “one prime”).
The phosphate group is attached to the 5′ carbon of one nucleotide makes a nucleophilic attack on the OH group at 3′ carbon of the next nucleotide and forms a phospho di ester bond , linking the nucleotides together.
The two strands strands of DNA are twisted around each other to form a right-handed double helix.
Base-pairing takes place between a purine and pyrimidine: namely, A pairs with T, and G pairs with C.
This is the basis for Chargaff’s rule i.e., due to the complementarity of the bases , there is as much adenine as thymine in a DNA molecule and as much guanine as cytosine.
Adenine and thymine are connected by two hydrogen bonds, and cytosine and guanine are connected by three hydrogen bonds.
The two strands of DNA are anti-parallel in nature; that is, one strand will have the 3′ carbon of the sugar in the “upward” position, whereas the other strand will have the 5′ carbon in the upward position.
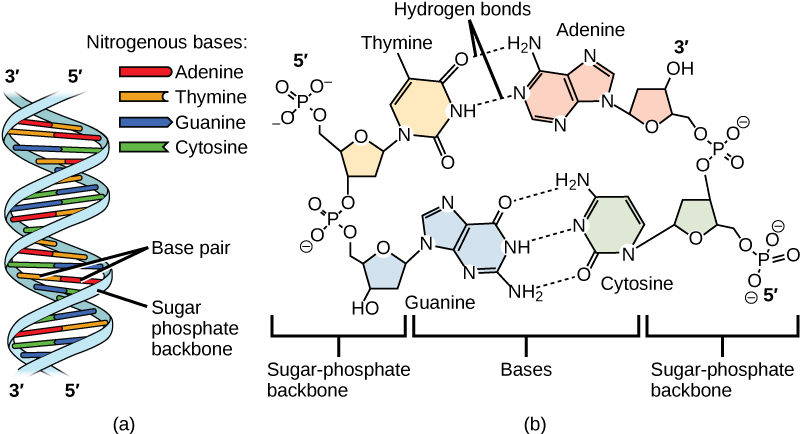
“DNA” by Charles Molnar and Jane Gair is licensed under CC BY 4.0
The Structure of RNA
There is a second polymer of nucleotides in the cell , called ribonucleic acid, or RNA.
Each of the nucleotides in RNA is made up of
- a nitrogenous base- namely adenine, guanine, uracil and cytosine (they do not contain thymine, which is instead replaced by uracil, symbolized by a “U.)”
- a five-carbon Ribose sugar, and
- a phosphate group.
Ribose has a hydroxyl group at the 2′ carbon, unlike deoxyribose, which has only a hydrogen atom
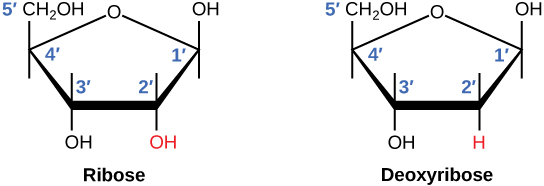
“Ribose and Deoxyribose” by Charles Molnar and Jane Gair is licensed under CC BY 4.0
Unlike DNA which is double stranded , RNA exists as a single-stranded molecule.
Based on their function , RNA is classified int o three types namely: messenger RNA (mRNA), transfer RNA (tRNA), and ribosomal RNA (rRNA)
All of these RNA molecules are involved in the production of proteins from the DNA code.
Test your Understanding
To know more about DNA packaging in to the nucleus visit the chapter on Eukaryotic gene organization – Packaging of DNA to Chromosome, from Understanding Gene Regulation and Gene expression
DNA Replication
When a cell divides, each daughter cell receives an identical copy of the DNA.
This is accomplished by the process of DNA replication which occurs during the synthesis phase, or S phase, of the cell cycle, before the cell enters mitosis or meiosis.
During DNA replication, each of the two strands of the DNA double helix serves as a template from which new strands are copied.
The new strand will be complementary to the parental or “old” strand.
Each newly formed DNA double strand consists of one parental strand and one new daughter strand. This is known as semiconservative replication.
The two DNA copies formed have an identical sequence of nucleotide bases and are divided equally into two daughter cells.
DNA Replication in Eukaryotes
The eukaryotic genomes are very complex and therefore DNA replication is a very complicated process
It involves several enzymes and other proteins.
It occurs in three main stages namely : initiation, elongation, and termination.
Initiation
There are specific nucleotide sequences called origins of replication at which replication begins. As eukaryotic DNA is very long there are multiple origins of replication on the eukaryotic chromosome
Certain proteins called Origin Recognition Complexes ( ORCs) bind to the origin of replication
An enzyme called helicase unwinds the DNA and opens up the DNA helix.
As the DNA opens up, Y-shaped structures called replication forks are formed .
Two replication forks are formed at the origin of replication, and these get extended in both directions as replication proceeds.
Replication can occur simultaneously from several Origins in the genome.
Elongation
During elongation, an enzyme called DNA polymerase adds DNA nucleotides to the 3′ end of the template.
But DNA polymerase requires a primer for its action.
Therefore a short stretch of RNA is synthesised by an enzyme called Primase, serves as the primer.
This primer is removed later, and the nucleotides are replaced with DNA nucleotides.
One strand, which is complementary to the parental DNA strand, is synthesized continuously toward the replication fork so the polymerase can add nucleotides in this direction. This continuously synthesized strand is known as the leading strand. Because DNA polymerase can only synthesize DNA in a 5′ to 3′ direction,
Whereas the other new strand is synthesized in short pieces called Okazaki fragments.
Each of the Okazaki fragments require a primer made of RNA to start the synthesis. T
The strand with the Okazaki fragments is known as the lagging strand.
As synthesis of the lagging strand proceeds, an enzyme called endonuclease removes the RNA primer, which is then replaced with DNA nucleotides, and the gaps between fragments are sealed by an enzyme called DNA ligase.
Termination
Telomere Replication
As eukaryotic chromosomes are linear, DNA replication comes to the end of a line in eukaryotic chromosomes. The DNA polymerase enzyme adds nucleotides in the leading strand until the end of the chromosome is reached; however, on the lagging strand there is no place for a primer to be made for the DNA fragment to be copied at the end of the chromosome.
This presents a problem for the cell which is referred as End Replication problem.
If this is not solved , over time these ends get progressively shorter as cells continue to divide.
The ends of the linear chromosomes are known as telomeres, which have repetitive sequences that do not code for a particular gene. As a consequence, it is telomeres that are shortened with each round of DNA replication instead of genes. These telomeres are synthesized by enzymes called telomerases
For example, in humans, a six base-pair sequence, TTAGGG, is repeated 100 to 1000 times.
The telomerase comprises of an an template RNA and a protein.
The RNA of Telomerase attaches to the end of the eukaryotic chromosome.
Complementary bases to the RNA template are added
Once the lagging strand template is sufficiently elongated, DNA polymerase can now add nucleotides that are complementary to the ends of the chromosomes.
Thus, the ends of the chromosomes are replicated.
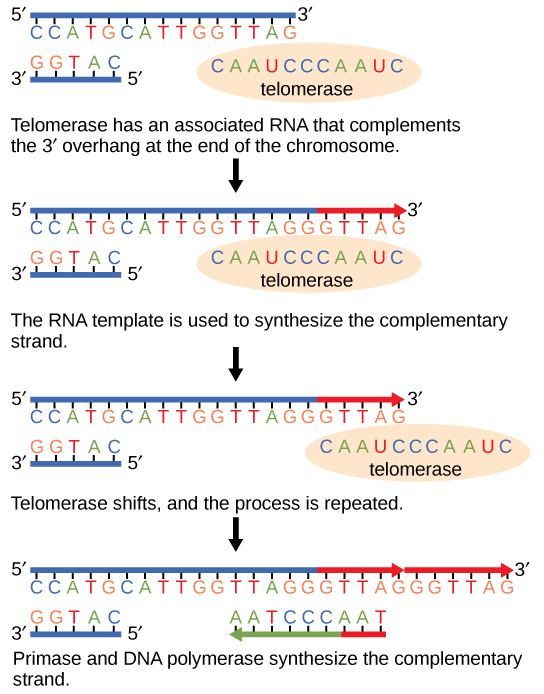
“Ends of eukaryotic chromosomes” by Charles Molnar and Jane Gair is licensed under CC BY 4.0
DNA Replication in Prokaryotes
The prokaryotic chromosome is a circular molecule with a less extensive coiling structure than eukaryotic chromosomes.
The 4.6 million base pairs that make up an Escherichia coli single circular chromosome are duplicated every around 42 minutes, beginning at a single replication origin and moving in both directions around the chromosome. Accordingly, about 1000 nucleotides are inserted per second. Compared to eukaryotes, the process is far faster.
DNA Repair
Errors can occur when DNA polymerase adds nucleotides. Every newly inserted base is proofread.During the replication if incorrect bases are added , the incorrect bases are removed and substituted with the proper ones by the Proof reading activity of DNA polymerase and the DNA polymerization proceeds .
The majority of errors are fixed during replication, however in cases when this is not possible, the mismatch correction process is used. The incorrectly integrated base is identified by mismatch repair enzymes, which then remove it from the DNA and replace it with the proper base
Another kind of repair, known as nucleotide excision repair, involves unwinding and separating the DNA double strand, removing the erroneous bases along with a few bases on the 5′ and 3′ ends, and then using DNA polymerase to duplicate the template and replace them .
Nucleotide excision repair is very crucial in the correction of thymine dimers formed by UV light . Two thymine nucleotides next to one another on a single strand are covalently bound to one another instead of their complementary forming a thymine dimer. A mutation will result if the dimer is not taken out and fixed. People who have defects in their genes that repair nucleotide excision are extremely sensitive to UV light and develop skin cancer
To know about other molecular process Transcription and Translation visit the chapters from Understanding Gene Regulation and Gene expression
